
Key practices for securing sensitive information in pipelines with Digibee
Securing sensitive information while building scalable integrations is crucial. Data security doesn't just involve encryption — it encompasses a comprehensive approach to how data is handled, protected, and audited.
In this use case, you’ll explore best practices for securing sensitive data and how to implement security measures in your pipeline-building process within the Digibee Integration Platform.
The focus of this article will reside on four aspects of pipeline security:
Encryption
Hashing
Obfuscation of sensitive fields
Management of authentication credentials through Accounts
Encryption: A foundation for securing sensitive data
One of the primary ways to safeguard sensitive data is through encryption. Think of encryption as a secure lockbox: the public key is like a padlock that anyone can close, but only the person with the matching private key (the unique key) can open it. This ensures that even if someone intercepts the lockbox, they can’t access its contents without the private key.
When implementing encryption and decryption within the Digibee Integration Platform, the Asymmetric Cryptography connector acts as this lockbox system, enabling secure data management by leveraging public and private key pairs. This connector supports two primary operations — Encrypt and Decrypt — where the data is encrypted using a public key and decrypted with the corresponding private key.
In contrast, the Symmetric Cryptography connector uses the same key for both encryption and decryption, making it more efficient for scenarios where performance is a priority. Symmetric encryption is typically used for encrypting large volumes of data, while asymmetric encryption is preferred for scenarios requiring higher security, such as secure key exchanges.
Enhancing pipeline security with Digibee connectors
In this case, the focus will be on the Asymmetric Cryptography connector. However, Digibee offers many more security options that you can leverage to protect your data. To explore the full range of security connectors, visit our Documentation Portal.
Putting theory into practice: Securing sensitive data
Encryption plays a critical role in securing sensitive data as it flows through pipelines. For instance, imagine a financial service that handles sensitive customer data, such as credit card numbers and personal identification information. The pipeline must ensure that this information remains secure as it passes through various processes.
The following sequence diagram provides a high-level overview of the solution, illustrating how encryption and decryption can be applied within a pipeline.
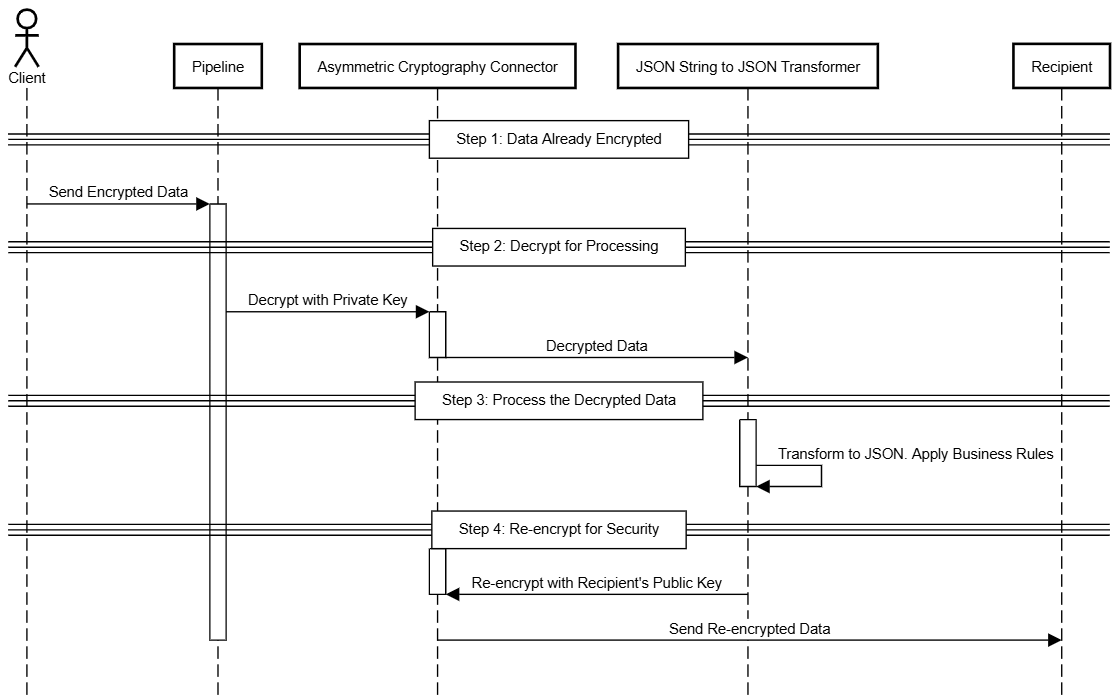
Here’s a breakdown of the implementation:
Start with data already encrypted
For this example, imagine that sensitive data (such as payment details) arrives at the pipeline already encrypted by the customer. This ensures that the information is secure from the very beginning.
Decrypt for processing
Once the data reaches the pipeline, it’s decrypted using the Asymmetric Cryptography connector.
A private key is used to access the encrypted data securely.
Process the decrypted data
Once the data is decrypted, the pipeline first transforms it into a structured JSON object using the JSON String to JSON Transformer connector.
After the data is properly formatted, the pipeline performs necessary actions, such as validation and transformations.
Re-encrypt for security
After processing, the data is encrypted again using the recipient's public key before being sent to another service or stored securely. This adds an extra layer of protection during transmission or storage.
Hashing: A secure approach to duplicate prevention
Unlike encryption, hashing is a one-way process that can’t be reversed, meaning that once data is hashed, it can’t be reconstructed into its original form. This makes hashing an ideal solution for verifying data integrity and storing sensitive information that doesn’t require decryption, such as passwords.
For instance, hashing can be used to manage user registration by preventing duplicate entries. Applying a hash to specific fields, such as a user’s email address, ensures that requests are unique.
Understanding the Hash connector
The Hash connector is designed to generate a unique digital fingerprint — a hash — for any given data input. It allows users to hash fields, payloads, or files. Users can select from a wide range of hashing algorithms and adjust parameters like salt and cost factor, among others.
Putting theory into practice: Preventing duplicate data with hashing
Imagine a financial institution that processes loan applications. One of the key pieces of data for identity verification is the Social Security Number (SSN).
Here's how hashing can prevent duplicate SSNs while maintaining security in your integrations:
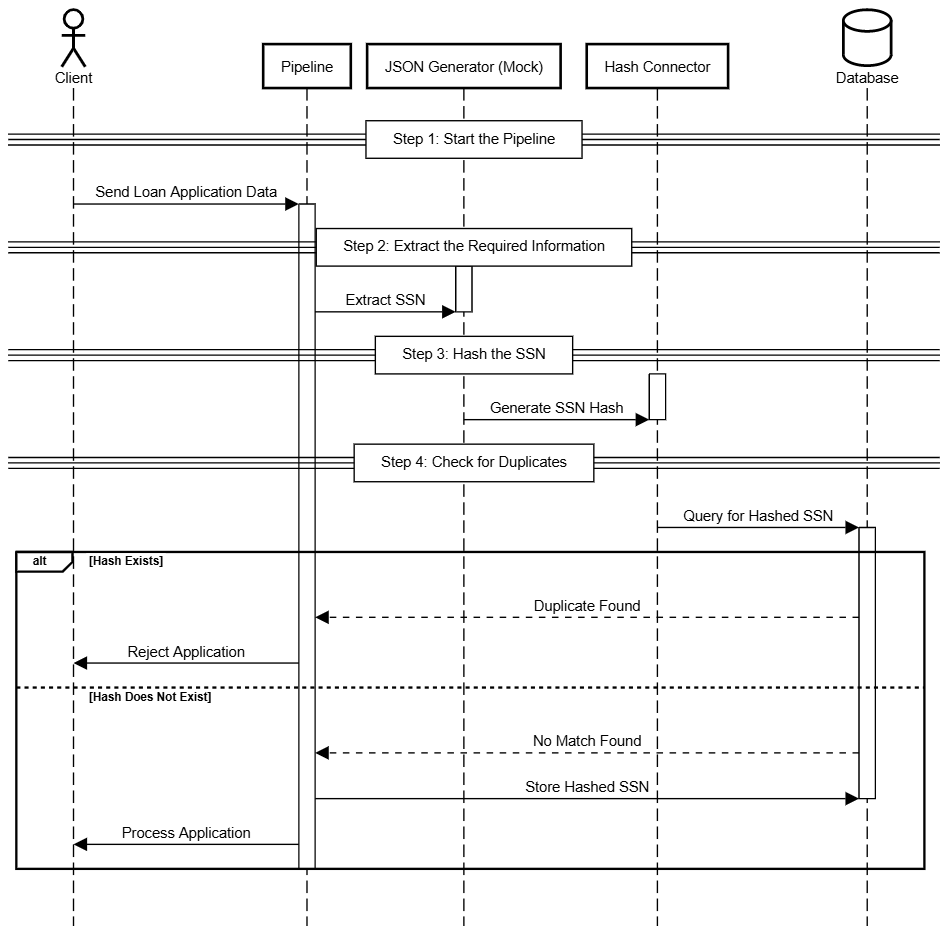
Here’s a breakdown of the implementation:
Start the pipeline
Begin by setting up an integration that receives data about a customer loan application. For simplicity, assume it’s a REST Trigger, although other triggers can be applied.
Extract the required information
Use a transformation connector (such as JSON Generator (Mock), Transformer (JOLT), or other) to extract the customer's SSN from the application payload. This SSN will be used to verify if a duplicate entry already exists in the database.
Hash the SSN
Pass the SSN through the Hash connector to create a digital fingerprint of the SSN.
Check for duplicates
Compare the hashed SSN with existing entries in the database:
If the hash exists: The system flags the SSN as a duplicate and prevents further processing of the loan application.
If the hash doesn’t exist: The SSN is recognized as unique, and the process continues to the next connector.
Prevent duplicate applications:
Store the newly generated hash in the database to mark the SSN as registered.
Any future applications with the same SSN will be flagged as duplicates and blocked from further processing.
Sensitive field obfuscation
Logging is critical for troubleshooting, but it’s equally important to ensure that sensitive data remains protected. To address this, you can configure Sensitive fields within the pipeline itself, ensuring that specific data is obfuscated or masked in the logs. These fields will appear obfuscated with the "***" character set in the log output.
In addition to pipeline-level configurations, you can also create a Sensitive fields policy that allows you to define policies at a realm-wide level. This policy applies across all pipelines within the realm, making it easier to standardize data protection across multiple integrations.
Log obfuscation of sensitive fields requires additional processing resources and memory. The impact on performance depends on the number of sensitive fields configured and the size of the message.

Leverage Accounts for enhanced security
In addition to the previous measures, managing accounts securely is a critical part of protecting sensitive information in pipelines. Accounts enhance the security of credentials such as passwords, private keys, and API tokens, among others.
With Accounts, you can store sensitive data securely, ensuring that your team can use the credentials within integration flows without directly accessing the sensitive values. This allows you to lock the credentials, ensuring that only authorized systems and services can use them in integrations, while team members can’t view or modify the sensitive values.
This secure management of authentication credentials ensures that you’re protecting not just the data flowing through your pipelines but also the access controls that govern it, adding another layer of defense against potential leaks or unauthorized access.
Final thoughts
Security is a shared responsibility among all teams involved in integration development. Each team member has a role in implementing and maintaining security practices to minimize risks. This collaboration leads to secure and reliable integrations.
Explore more possibilities in our Documentation Portal, take courses on Advanced Security at Digibee Academy, or visit our Blog to discover more resources and insights.
If you have feedback on this Use case or suggestions for future articles, we’d love to hear from you through our feedback form.
Last updated
Was this helpful?