
Automating file storage with Digibee
Daily file uploads and downloads are crucial for business operations. But even small mistakes in managing files can lead to delays, compliance issues, or data loss.
With Digibee, you can make sure files are handled accurately and reduce the need for manual work in these important tasks. This lowers the chance of human error and improves productivity, letting teams focus on more strategic tasks instead of routine file management.
Why automating file management matters
In many industries, manual file processing is both time-consuming and prone to errors. Automating these processes with Digibee ensures that files are handled accurately and securely.
Use cases
Banking: A bank manages hundreds of daily emails with customer financial reports. By setting up automated file handling, these reports are securely uploaded, processed, and ready for review and analysis.
Supply chain: A supply chain company can automate the consolidation of files like invoices, inventory records, and packing lists from multiple suppliers and distributors.
Retail: A global retailer can synchronize product inventory files from various suppliers into a centralized system, avoiding inventory discrepancies, lost sales, and reduced efficiency.
In all these use cases, automating file operations eliminates the need for manual intervention, allowing businesses to process file contents quickly and securely without direct interaction.
Getting started: Automating your file processing pipelines
You can improve your workflow with Digibee by automating file processing pipelines as they are integrated in your processes. Below you can see which triggers can kickstart these file processing pipelines, helping you optimize your workflow based on your needs.
Triggers to initiate automation
Scheduler Trigger: Configure your pipeline to run at set intervals using CRON expressions. This allows the pipeline to check for a specific file in designated storage at these scheduled times.
Email Trigger: Automatically process files received via email. The pipeline is triggered as soon as a file attachment arrives in the monitored inbox.
HTTP File Trigger: This trigger supports both uploads and downloads of files over 5 MB via HTTP.
Understanding file handling
While automation simplifies file management, it's essential to understand the technical difference between reading the content of a file or downloading it. Reading loads the file into execution memory, while downloading saves it to disk without using memory — a crucial distinction for many use cases.
This setup optimizes workflows and avoids inefficiencies, especially with large files. For example, handling files that exceed memory limitations can lead to out-of-memory errors, so understanding these distinctions is key to designing effective file processing pipelines.
By reading file contents only when necessary and using pagination techniques for large files, your team can prevent performance issues.
Storing files: Digibee and third-party options
Once file processing begins, you can explore storage options. Digibee integrates with both native and third-party solutions to suit various needs. Here’s a closer look:
Storage connectors
Digibee Storage: Digibee’s native storage connector allows you to list, download, upload, and delete files within your realm. Please note that this storage option is available only for Digibee clusters. If you are using a private cloud, the Digibee storage connector may not be accessible.
It is recommended to store files temporarily and implement a cleanup routine to remove files that are no longer needed for active processes.
Third-party storage: Use connectors for Amazon S3, Microsoft OneDrive, Google Cloud Storage, and others to interact with external cloud storage services.
Building your pipeline
The diagram below provides a high-level overview of an implementation process for uploading a file to storage after enrichments and transformations. You can design your pipeline to accommodate the operations needed, as each integration scenario presents a unique use case.
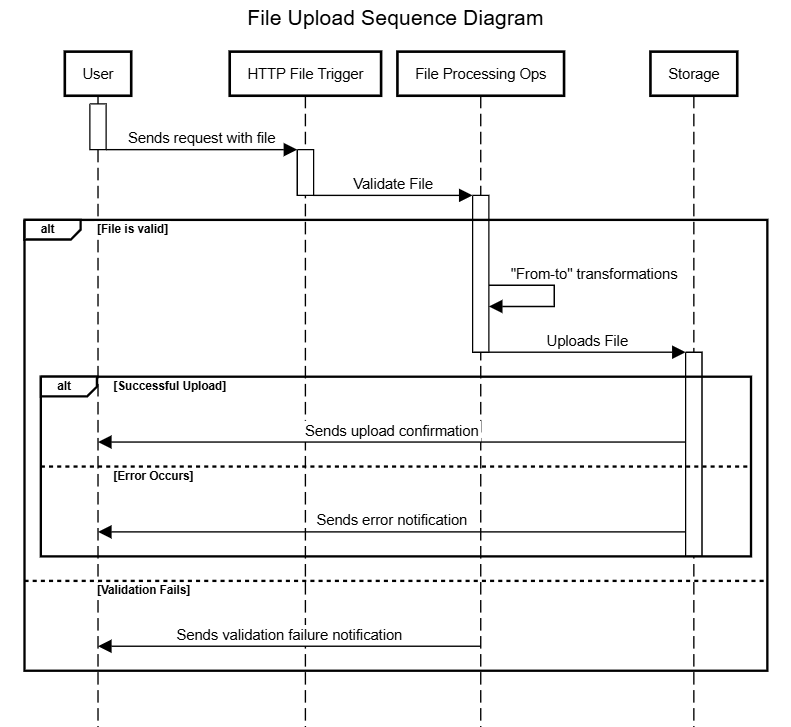
Pipeline overview
Trigger: The flow of the pipeline begins with an HTTP File Trigger, which creates an endpoint for receiving files from external services.
File validation: You can implement validation strategies to ensure file format meets the required criteria. Options include using the Validator V2 connector, the Choice connector, or the Assert V2 connector that can be employed to create an interruption of the execution when a defined condition isn’t met.
File processing: After the file is received, the pipeline performs file processing tasks such as transformation and enrichment. You can leverage stream connectors like Stream File Reader and Stream JSON File Reader for this purpose. These connectors enable batch execution where each resulting line or row from the file is individually processed through a subflow. This batch approach can also work with asynchronous pipeline architectures, making them adaptable to different processing needs.
When using stream connectors, it's important to note that exceptions don’t stop the flow. Instead, they trigger the OnException subflow, allowing the pipeline to continue processing the next line of the file until completion.
Storage: After completing the necessary transformations, you can upload the newly processed file to the appropriate storage. If you need to write the file, you can use the File Writer connector. Once the file is written, you upload it to the appropriate storage, either leveraging Digibee Storage or a third-party option like Amazon S3, Google Cloud Storage, or Microsoft OneDrive, among others.
Error handling: Error handling can be implemented to track the success or failure of the selected storage operation, ensuring any issues are promptly addressed.
Output: The final output generated by the pipeline must be configured. This involves creating a structured response, which can be accomplished using a connector like JSON Generator.
Final thoughts
Automated file management pipelines are essential to ensure reliable file handling to minimize manual errors, save time, and improve operational accuracy. You can explore more possibilities in our Documentation Portal, take courses on Working with Files in Digibee at Digibee Academy, or visit our Blog to discover more resources and insights.
If you have feedback on this Use Case in Action or suggestions for future articles, we’d love to hear from you. Share your thoughts through our feedback form.
Last updated
Was this helpful?