
Best practices for error handling in pipelines
Learn how to implement efficient error handling in your pipeline and improve the reliability of your integrations.
Proper error handling is essential to ensure the stability, predictability, and reliability of the integrations built on the Digibee Integration Platform. Without effective error management, pipelines can behave unexpectedly, making maintenance difficult and impacting critical processes. This article presents best practices for efficient error handling.
Using Fail On Error and OnException
Fail On Error
This option is available in the configurations of most Platform connectors. When enabled, the pipeline execution is interrupted. In connectors that use subflows, an exception is sent to the OnException flow.
OnException
OnException is present in some connectors with subpipelines such as Do While, For Each, and Retry, and plays an important role in capturing controlled errors. It allows error handling to be centralized at a single point in the pipeline, making future adjustments, analysis, and additions easier, and avoiding repetition of logic throughout the pipeline.
Error summary in loop connectors (For Each, Do While)
The OnException of loop connectors such as For Each doesn’t interrupt the execution of the loop. This makes it possible to collect or summarize all exceptions that occur during execution and handle them after the loop ends. For more information, see the official For Each documentation.
A recommended practice is to store an error summary in the pipeline memory to display it later using the Add item to session (array) capsule. This capsule inserts records into an array called resultList, which can be retrieved later.
A JSON object must be included in the payload to properly add an item to the array:
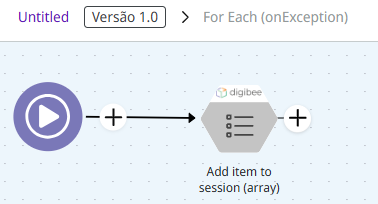
If the capsule is not available, it’s also possible to perform this directly in the pipeline using other available connectors, like Session Management and JSON Generator:
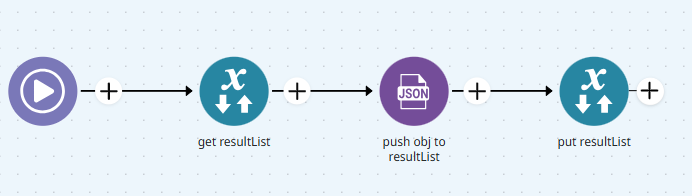
This approach should be used with caution, as memory consumption increases as records are added to the array. For large iteration volumes, it's recommended to use Object Store with the Isolated parameter enabled, as it’s a more appropriate alternative.
Reviewing timeouts for external connection connectors in relation to the trigger
When configuring a pipeline, it’s crucial to consider the timeout of external connection connectors (REST, DB, SOAP, MongoDB) in relation to the timeout defined in the trigger.
Importance of aligning timeouts
The trigger timeout should be greater than the sum of the timeouts of all external connectors. This ensures that the pipeline has enough time to handle potential errors before it’s terminated.
Impact of response times on the pipeline
If external connectors have long timeouts and the trigger has a lower value, the pipeline may terminate before the requests are completed, leading to inconsistencies and making error identification more difficult.
For example, if a pipeline has three REST connectors, each with a 30-second timeout, the total execution time can reach 90 seconds. If the trigger is configured with a timeout shorter than this value, the pipeline will terminate before the connectors finish their execution.
Tips for setting timeout values
Calculate the sum of timeouts for external connectors and add a safety margin to the trigger timeout.
Avoid excessively high values, as they may affect the platform's performance.
Consider internal pipeline processes, such as transformations and error handling, when defining the trigger timeout.
Regularly monitor connector execution time and adjust timeouts as needed.
Error validation in pipelines with heavy Object Store usage
When a pipeline performs multiple CRUD (Create, Read, Update, Delete) operations on an Object Store collection, especially concurrently across different flows, it’s critical to follow best practices to avoid inconsistencies and unexpected failures.
Preventing errors in concurrent operations
Consider the following practices:
Enable the Fail On Error option in connectors accessing the Object Store to automatically capture failures.
Monitor simultaneous access to the Object Store to avoid overload and concurrency-related failures.
Implementation example
If a pipeline reads from the Object Store and then updates the data, an error may occur if another process modifies or deletes that data before the update. To mitigate this risk, it’s recommended to:
Verify the data after reading, ensuring it’s still available.
Use the Assert connector to validate the presence of expected data.
Apply the Choice connector to define alternative routes if the data has been changed or removed.
These practices help minimize failures and improve reliability in Object Store interactions.
Specific behavior of the Retry connector
The Retry connector has its own rules for error handling, described in this documentation. It's important to understand how the OnProcess and OnException blocks behave in the Retry context.
If OnProcess contains a Throw Error connector or has the Fail On Error parameter enabled, and OnException also includes a Throw Error, Retry will immediately stop its attempts, even if there are retries remaining.
Recommendation: To ensure Retry continues its attempts until the configured limit is reached, avoid using Throw Error in OnException. This allows the pipeline to continue executing retries before completely failing.
“Connection redundancy” in the DB V2 connector
When the DB V2 connector’s connection string includes two or more servers, the timeout defined in the Custom Connection Properties field is applied individually to each server.
For example, with two servers and a 30-second timeout:
The first attempt will use 30 seconds to connect to the first server.
If it fails, the connector will try the second server, applying another 30 seconds.
Database connection management
Connection management should align with integration flow needs. Poor configuration may lead to:
Too many open connections, affecting both database and pipeline performance.
Unnecessary resource use, compromising scalability and stability.
Optimization recommendations
Reviewing and adjusting connection parameters can improve pipeline performance and reduce database impact. Key parameters include:
Pool Size By Actual Consumers – Sets pool size based on the number of actual consumers.
Exclusive DB Pool – Indicates whether the pipeline has a dedicated pool.
Custom Pool – Allows defining a custom pool.
Keep Connection – Keeps the connection active between executions, which may impact resource usage.
For high-volume operation flows, reviewing these settings is essential for performance and avoiding overload.
Conclusion
Proper error management in the Digibee Integration Platform is essential to ensure integration stability and efficiency. As we've seen throughout this article, it's important to:
Properly configure the Fail On Error and OnException connectors.
Understand specific behaviors of the Retry and DB V2 connectors.
Define appropriate timeouts for external connectors and align them with the trigger.
Use validations in concurrent flows with Object Store to avoid inconsistencies.
Applying these best practices makes the pipeline more resilient and helps with faster issue detection and resolution. We also recommend periodically reviewing your error-handling strategies and configurations to keep up with evolving integration needs.
With a structured approach, you can ensure that the solutions developed on Digibee are robust, reliable, and scalable.
Last updated
Was this helpful?