
How to use Event-driven architecture on the Digibee Integration Platform
Event-driven architecture (EDA) is a design approach where independent applications or microservices communicate asynchronously through events. An event communicates a state change, such as the creation of a new user account or submission of a product review. These events are sent out without knowledge of which consumers will respond to them.
Key components in EDA include:
Event producers: Sources of events triggered by state changes or actions.
Event consumers: Services that react to events and execute actions in response.
Event brokers: Act as intermediaries, ensuring that events are delivered from producers to consumers.
In this article, you’ll explore the core principles of EDA and learn how to implement them in your integrations using the Digibee Integration Platform through a practical use case.
Benefits of an Event-driven architecture
While the following benefits are described in the context of integrations, they apply broadly to EDA in general:
Asynchronous processing: Allows integrations to handle events independently, enhancing scalability.
Decoupling: Producers and consumers are unaware of each other, boosting flexibility.
Scalability: Integrations can scale modularly, enabling independent scaling of services to handle fluctuating loads.
Reliability: Failures are isolated to individual services, ensuring that the rest of the integrations continue to function.
Real-time responsiveness: Consumers can independently prioritize their functions and react to events as they occur.
Leveraging Event-driven architecture with Digibee
Digibee employs an event-driven architecture based on the publish-subscribe (pub/sub) pattern, where events are published to a broker and consumed by subscribers.
The following connectors collaborate to streamline event processing:
Event Publisher: A connector that publishes events with minimal configuration, including defining event name and specifying the event payload.
Event Trigger: Listens for specific events and initiates processes based on the event payload.
Pipeline Executor: A connector that enables both synchronous and asynchronous calls to other pre-deployed pipelines.
Integration with Third-Party Event Brokers
Digibee can integrate with Third-party brokers like RabbitMQ, AWS SQS, and Kafka, allowing you to combine Digibee’s capabilities with external solutions. See the documentation for queues and messaging connector for more information.
For example, the JMS Trigger uses external JMS queues, while the Event Publisher + Event Trigger pair relies on Digibee’s internal queues. Despite the difference in where the queues are hosted, both approaches work similarly in triggering and processing events.
Scenarios for using Pub/Sub pattern
Triggering multiple tasks simultaneously: By publishing events to various subscribers, so tasks can be independently executed.
Decoupling integrations: Enables communication without direct dependencies, where integrations don’t need to wait for a response.
Coordinating asynchronous processes: Integrations can “collaborate” on tasks without immediate, synchronous communication.
Putting theory into practice
To fully grasp how EDA can be applied in real-world scenarios, let’s explore a practical use case. This example is divided into two parts: the Publisher pipeline and the Subscriber pipeline, each playing a specific role in the overall integration.
The sequence diagram below provides a high-level overview of this process, illustrating how each record is individually sent to the Subscriber Pipeline for processing.
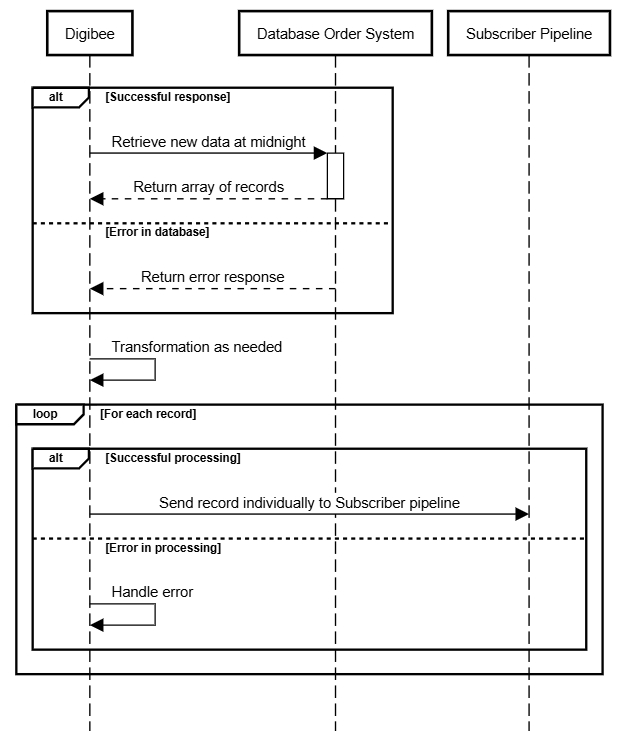
Part I: The Publisher pipeline
Imagine a retail company that needs to process daily order data and publish it as events for other integrations to consume. The goal is to automate this process by implementing a pipeline that:
Query a database for the day’s order data.
Validate the query response.
Publish each record to a subscriber pipeline for further processing.
Let’s walk through the step-by-step process:
Configuring the trigger The pipeline is triggered using the Scheduler trigger with the Midnight variable.
Querying the database The first step in the flow involves a database connector that executes a query to fetch the daily order data.
Validating the query response
If the query returns records (rowCount>0), the pipeline proceeds to the next step.
If the query returns no records, the pipeline returns a message with “no records to process”.
If the query returns an error, it follows the "error" path, where a Throw Error connector outputs the error.
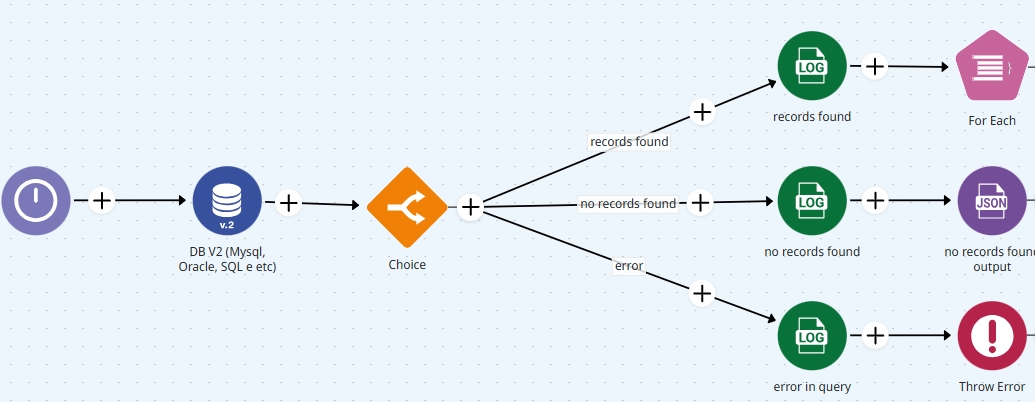
Pipeline scheduler at the root level with a database connector, leading to three possible execution paths.
Processing each record
The For Each connector iterates through the dataset, processing each record individually.
Within the iteration, a JSON Generator connector (or any other connector suited to the use case) transforms the data as needed.
Finally, the Event Publisher connector sends the processed record to the subscriber pipeline, ready for further integration purposes.
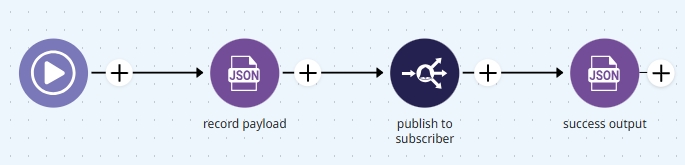
Final output
Once all records are processed, the pipeline completes its execution.
Part II - The Subscriber pipeline
Once the event is published from the Scheduler pipeline, the Subscriber pipeline comes into play:
Event Trigger
The pipeline is triggered when a new event is published by the Scheduler (pipeline #1).
Validation step
As a best practice, it is important to validate the incoming payload (Validator V2) against the expected schema, as the subscriber pipeline may receive events from multiple publishers.
Subsequent logic
After validation, the payload is transformed as needed and continues down the flow for further processing.

Final thoughts
By decoupling producers and consumers and enabling asynchronous communication, EDA allows your integrations to handle high event volumes, adapt to varying workloads, and maintain fault tolerance. Incorporating these principles into your integration strategy will not only enhance workflow performance but also prepare it to scale and evolve with your organization’s needs.
We highly recommend exploring the Event Driven Architecture courses I and II, as well as the EDA webinars available on Digibee Academy. You can also explore more possibilities in our Documentation Portal, or visit our Blog to discover more resources and insights.
If you have feedback on this 'Use case or suggestions for future articles, share your thoughts on our feedback form.
Last updated
Was this helpful?