
Improving integration performance with API pagination
When dealing with large datasets, loading all the data at once can impact efficiency, leading to slow response times, increased network traffic, and a frustrating user experience.
In this article, you’ll learn how you can leverage Digibee to address these challenges by implementing pagination techniques into your integrations to enhance overall application performance.
The challenges of unpaginated data
Without effective pagination, applications face several issues:
Slow load times: Users experience delays, affecting their interaction with the application.
Performance degradation: Applications may become unresponsive or crash due to excessive data loads.
Increased network traffic: Handling large volumes of data in single requests can degrade performance.
Time-outs and errors: High data volumes can lead to timeouts and out-of-memory errors.
Consider a customer management dashboard that needs to display thousands of records. Loading all entries at once would be inefficient and slow. Now, imagine an e-commerce platform that attempts to load all product listings in a single request. Both scenarios highlight the importance of pagination. By breaking down large datasets into smaller chunks, pagination can significantly improve performance and user experience.
Considerations for implementing pagination
General requirements: Evaluate data volume and time limit when deciding the appropriate pagination approach.
Server-side vs. client-side pagination: Decide whether to implement pagination on the server side, where the server returns only the required subset, or on the client side, where the entire dataset is loaded and paginated within the application.
Parallel processing: For large datasets and tight deadlines, use parallel processing techniques to accelerate data handling.
Event-driven architecture (EDA): Use paginated queries in conjunction with EDA to enhance data processing and responsiveness.
Putting theory into practice
For this example, you’ll focus on REST API pagination, a method commonly used in e-commerce platforms. In these scenarios, users navigate product catalogs using "Next" and "Previous" buttons, ensuring that only a portion of products is loaded per request.
While you will explore this specific API example in detail, it's important to note that pagination can also be applied in various contexts, as each integration scenario presents a unique use case.
Key concepts:
Offset: Specifies the starting point for data retrieval.
Limit: Defines the number of records to fetch in each request.
In practice, the offset will correspond to the page number, and the limit will represent the page size.
Example API request:
Setting up the solution
The diagram below offers a high-level overview of a proposed our architecture.
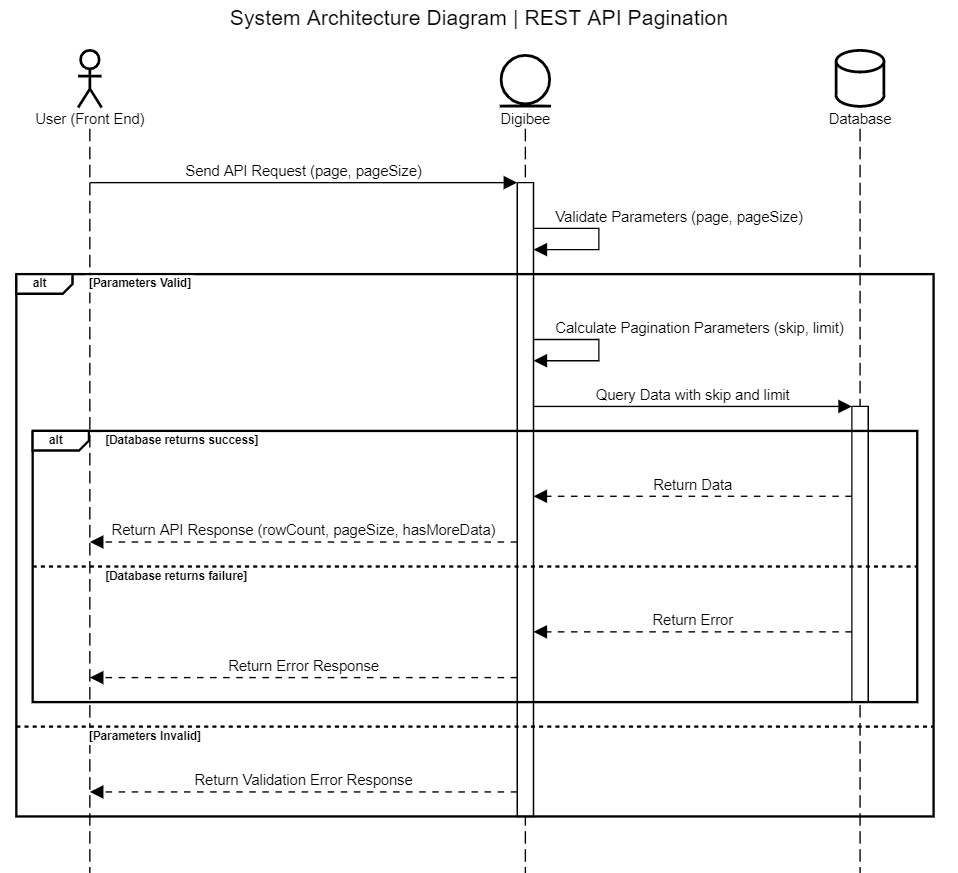
Pipeline implementation
This section explores how pagination is implemented in a pipeline.
API and validation: The pipeline is exposed as a REST API that accepts
pageandpageSizeas query parameters. A Validator connector ensures these parameters are valid and throws an error if parameters are invalid or missing. Additionally, the pipeline can impose apageSizelimit to maintain optimal performance.Calculating values: The pipeline calculates the
skipvalue (offset), which determines the starting point for data retrieval, based onpageandpageSize. Theskipvalue is computed by multiplying the page number by the page size and then subtracting the page size from the result.
For instance, if the user requests page 3 with a page size of 50, the calculation would be (3 * 50) - 50, which equals 100. This value determines the starting point for data retrieval. Meanwhile, the limit value is simply the pageSize.
Data retrieval: The pipeline queries the database using
skipandlimitto retrieve a specific data subset.Final Response: The final response may include information such as the retrieved data from the database, row count, page size, and even a
hasMoreDataflag indicating if more data exists.
Example:
User requests
page4 with apageSizeof 3.The pipeline retrieves data starting from record 9 (calculated
skip) and fetches 3 records (defined bypageSize).The response includes the retrieved data (3 user records) along with
rowCount(3),pageSize(3), andhasMoreData(true, indicating more data).
How response time is impacted by pagination
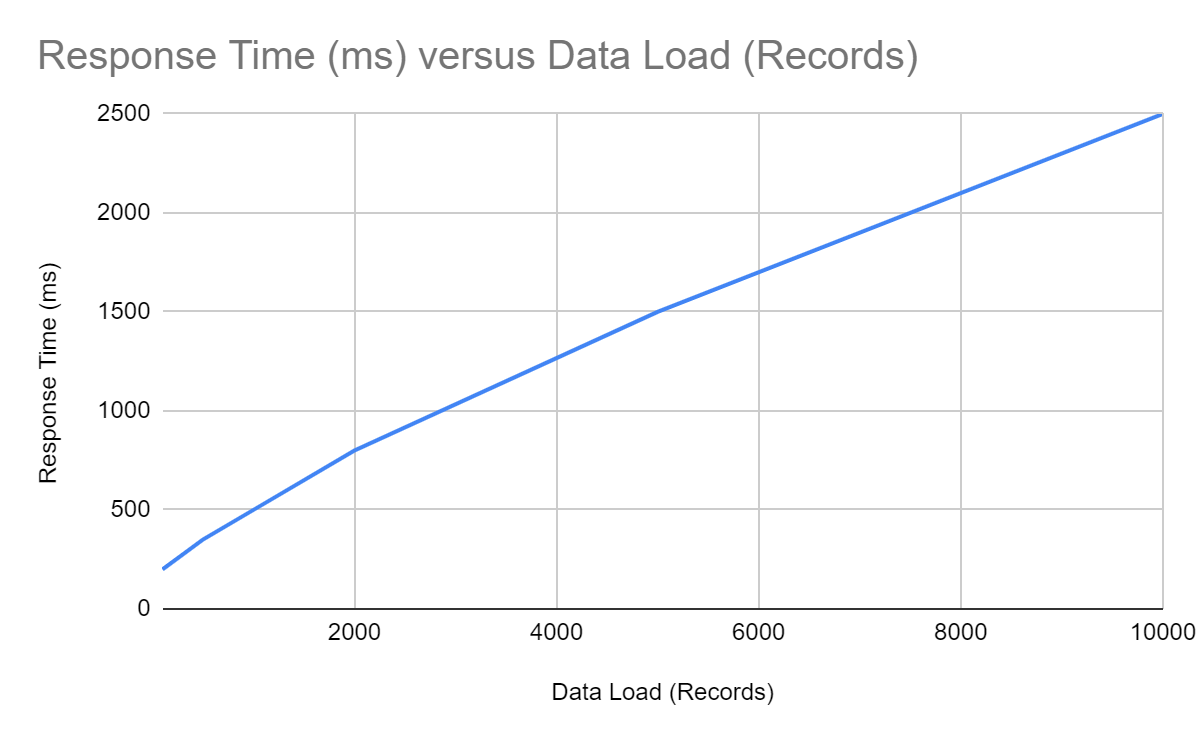
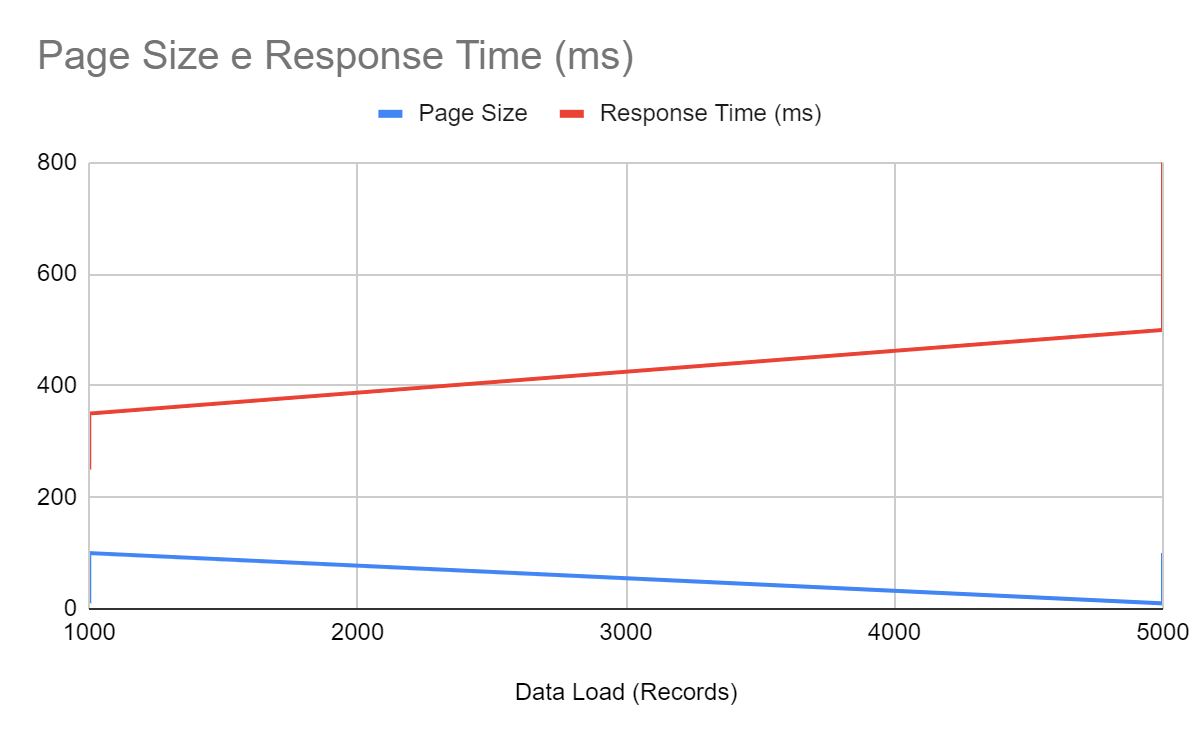
Without pagination (graph #1): Retrieving all records at once overloads the server, increasing processing time.
With pagination (graph #2): Improved response times by fetching data in manageable chunks.
Finding the right balance
While pagination significantly improves performance, it’s important to avoid extremes. Querying records both excessively large and overly small may also lead to excessive server overhead and inefficient network traffic. The key is to determine the optimal chunk size for your server. Experiment with different page sizes to identify the most efficient configuration for your specific use case.
Final thoughts
In a world of exponentially growing data, API pagination helps retrieve and display data effectively. You can explore more possibilities in our Documentation Portal, Digibee Academy for courses on Pagination, or visit our Blog to discover more resources and insights.
If you have feedback on this Use Case in Action or suggestions for future articles, we’d love to hear from you. Share your thoughts through our feedback form.
Last updated
Was this helpful?