
How to resolve common pipeline issues
Learn how to identify and resolve common errors in your pipelines.
What qualifies as an error?
In integrations, an error is a failure or unexpected behavior that interrupts the normal flow of data between systems, services, or connectors. These errors can occur at any stage of execution.
Examples of errors in integrations
Unexpected restarts
Description: When the integration infrastructure, such as pipeline containers, is restarted due to internal problems such as OOM errors.
Example: A pipeline that consumes a lot of memory leads to an automatic restart by Kubernetes and generates a “recycled” warning in the Runtime screen.
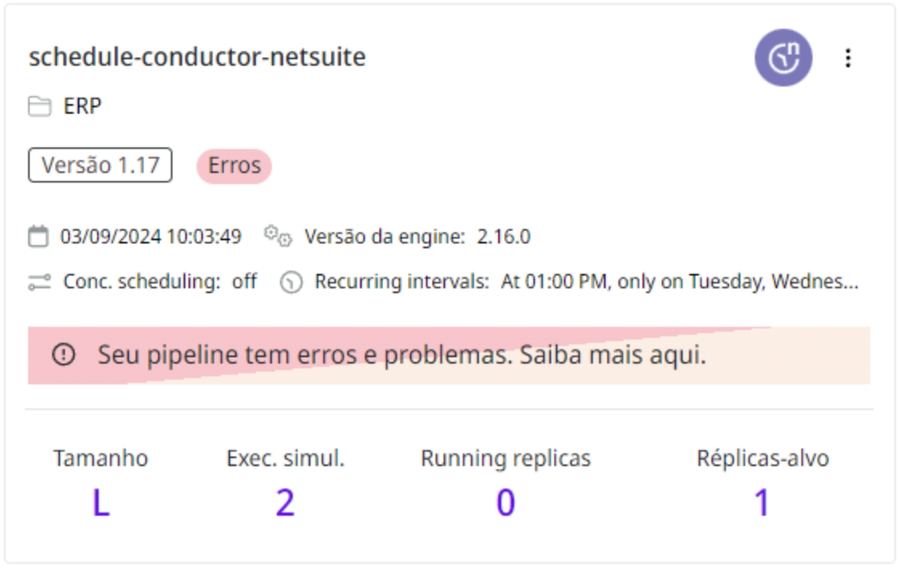
Step-by-step guide to identifying, analyzing, and solving issues
Identifying the issue
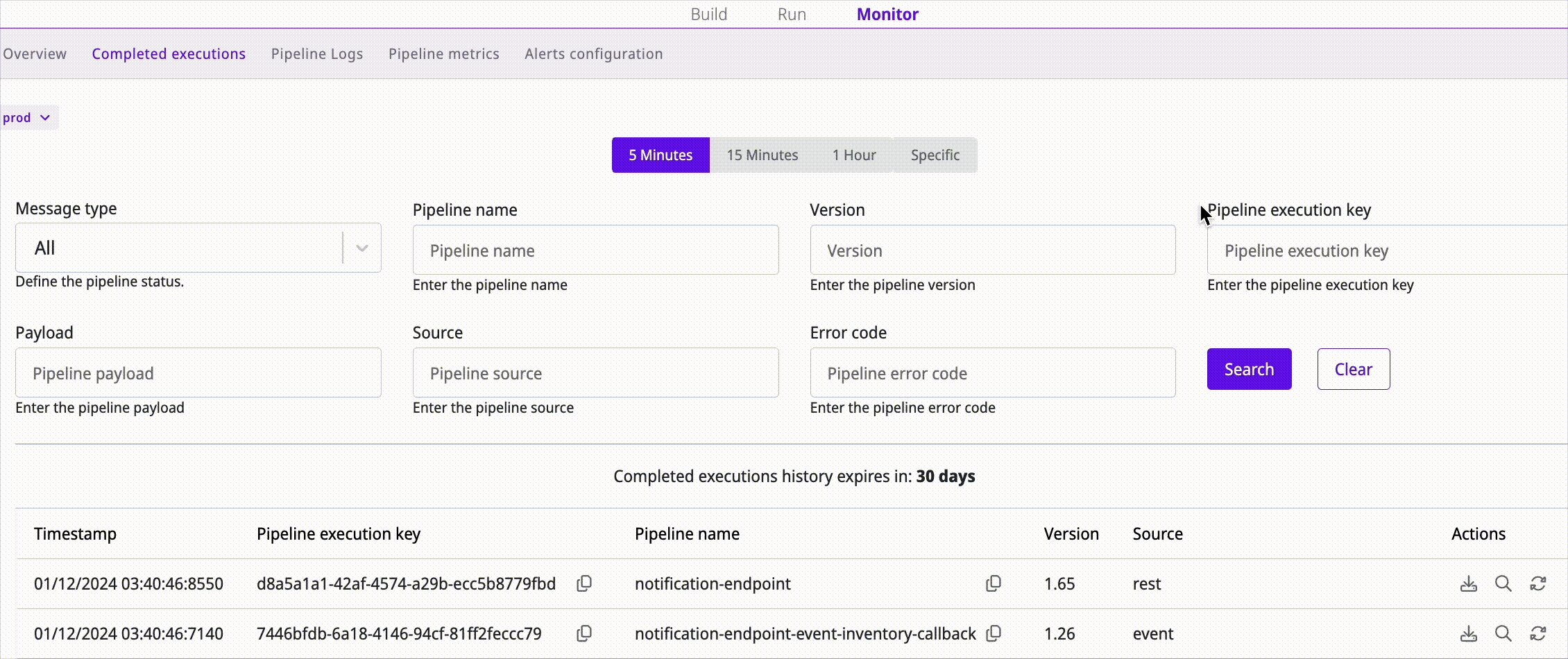
Access the pipeline and execution
Open two tabs: one for the examined pipeline and another for the associated execution on the Completed Executions page. This allows you to compare the configured integration (pipeline) with what actually happened (execution).
Build: Shows how your integration is configured.
Monitor: Shows execution details and possible error points.
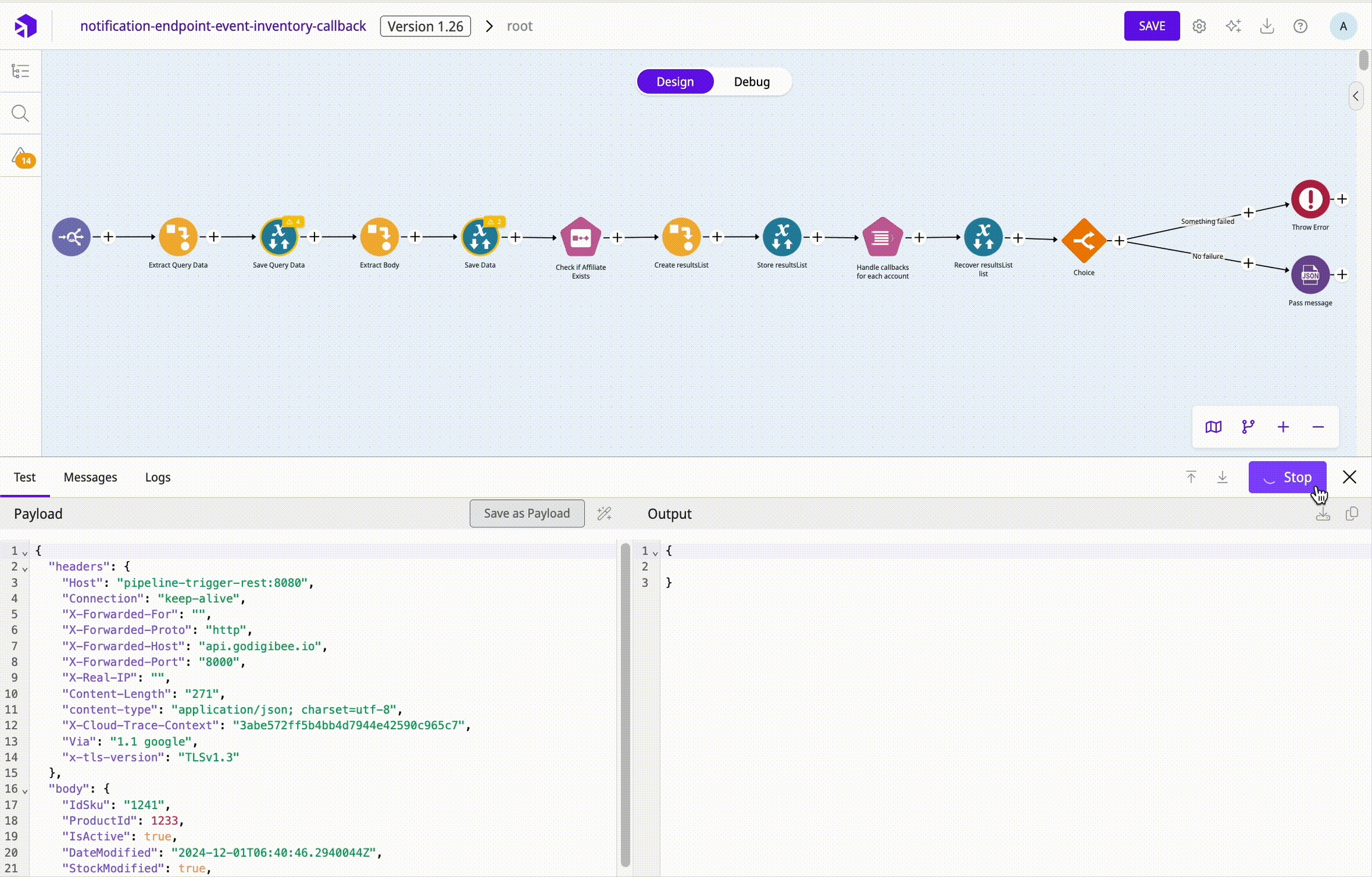
Analyze the logs
Check the execution logs to trace the integration path, to find the point at which the integration was aborted, or to identify the error. The logs can be analyzed individually or across multiple executions. You can view the logs in two ways:
Completed Executions: Displays the execution key, the input/output messages, and the start and end timestamps.
Pipeline Logs: Provides logs of the steps that were executed from the request to the pipeline response.
Not all pipeline connectors automatically generate logs. Connectors such as Log and external interaction connectors (for example, REST, Google Storage, Stream DB) always log messages. However, the results of data transformation or external connectors are only displayed if they are explicitly logged.
Analyzing the issue
Method 1
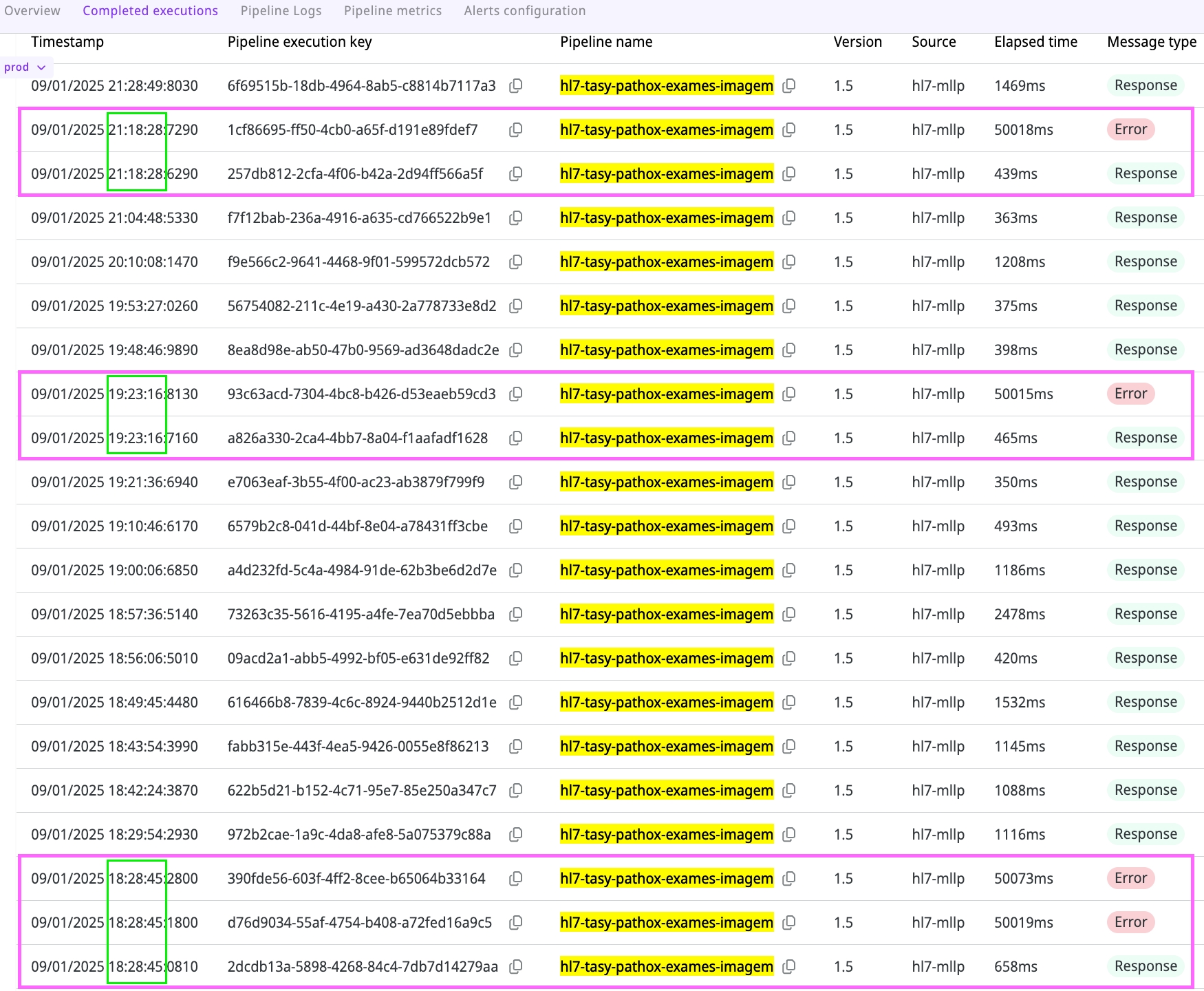
Compare a successful integration with a failed integration. Look for data that has been integrated correctly (for example, an order number) and data that has failed to integrate. If similar data follows different flows, compare the logs to find the point of divergence.
Method 2
Identify patterns in execution failures. For example, if concurrent executions fail with a timeout, analyze the logs to determine which step caused the issue and which connector or service is associated with it.
Resolving common issues
External tools support
Sometimes you can use external tools to help you with certain aspects of the integration:
SSL certificate validation: If you encounter connection issues, it can be helpful to check that certificates are correctly updated and active.
XML validation and comparison: For debugging errors in XML workflows and comparing successful executions with failed ones.
HTML generator: For creating HTML messages for use in connectors such as Email and Template Transformer.
JSON Schema generator: For generating schemas from a valid JSON file.
Mock data generator: Useful for testing with large amounts of data.
AI tools: For simplifying logical solutions such as the creation of RegEx.
Improving diagnostics
Pay attention to logs
Logs are crucial to quickly identify where errors occur in the pipeline. For effective diagnostics, we recommend placing the Log connector at strategic points in the pipeline. Place it before and after critical connectors, such as data transformations, calls to external services, and flow decisions. This will allow you to track the exact path of execution and pinpoint specific issues.
Monitor these logs regularly to identify error patterns or signs of poor performance. With the Log connector configured in key areas, you get a more detailed overview of execution, making it easier to track problems.
Check trigger and queue settings
Make sure that the pipeline trigger is configured correctly and that the queue expiration time is appropriate for the volume of data you are processing. Errors in the trigger or an expiry time that is too short can lead to the loss of important messages.
Configure the trigger to meet the requirements of the data flow and adjust the time in the queue if necessary to ensure that the messages have enough time to be processed. Pay attention to the expiration time of the event queue and regularly check the lifetime of the messages in the queues.
Review pipeline implementation
You can use an Assert to check whether the data returned by external services matches the expected format, which ensures a more robust integration.
Monitor deployment settings
Deployment settings such as the number of Replicas, Concurrent executions, and memory allocation (Pipeline size) have a significant impact on pipeline performance. Ensure that the memory and replicas are appropriately sized for the expected workload, especially for pipelines with high demand.
Adjust these settings as needed to ensure stable performance and minimize execution errors.
Use Digibee monitoring tools
The Digibee Integration Platform provides monitoring tools and insights to detect issues such as increased response times or unusual error rates. Enable these tools to monitor pipeline health in real time and receive proactive alerts about performance or configuration issues.
Alerts Configuration: On this page, you can customize integration performance notifications based on metrics to take quick action to minimize operational impact. Learn more in the Alerts documentation.
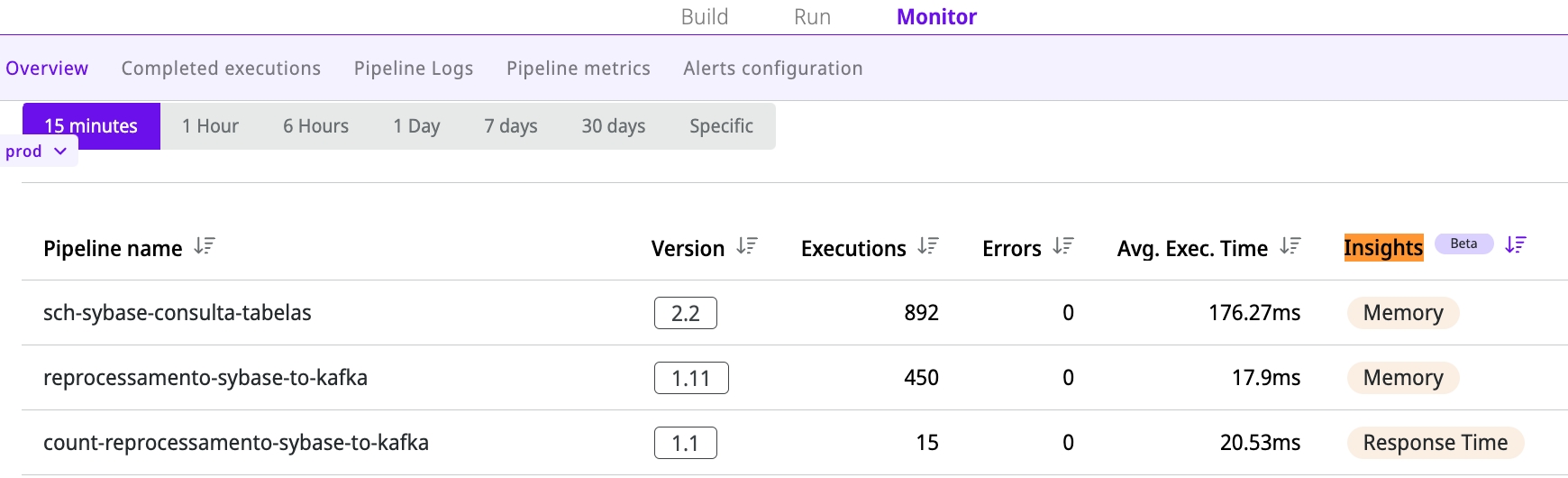
Monitor Insights: This feature provides you with insights into the health of completed integrations. Selecting an insight takes the user to the metrics of the executions that require attention, already filtered by the time period of occurrence. Further information can be found in the Monitor Insights documentation.
Manually reprocess executions
This feature allows you to retry previously processed calls, which is useful in scenarios where the original call failed due to temporary issues such as network interruptions or errors in the target system.
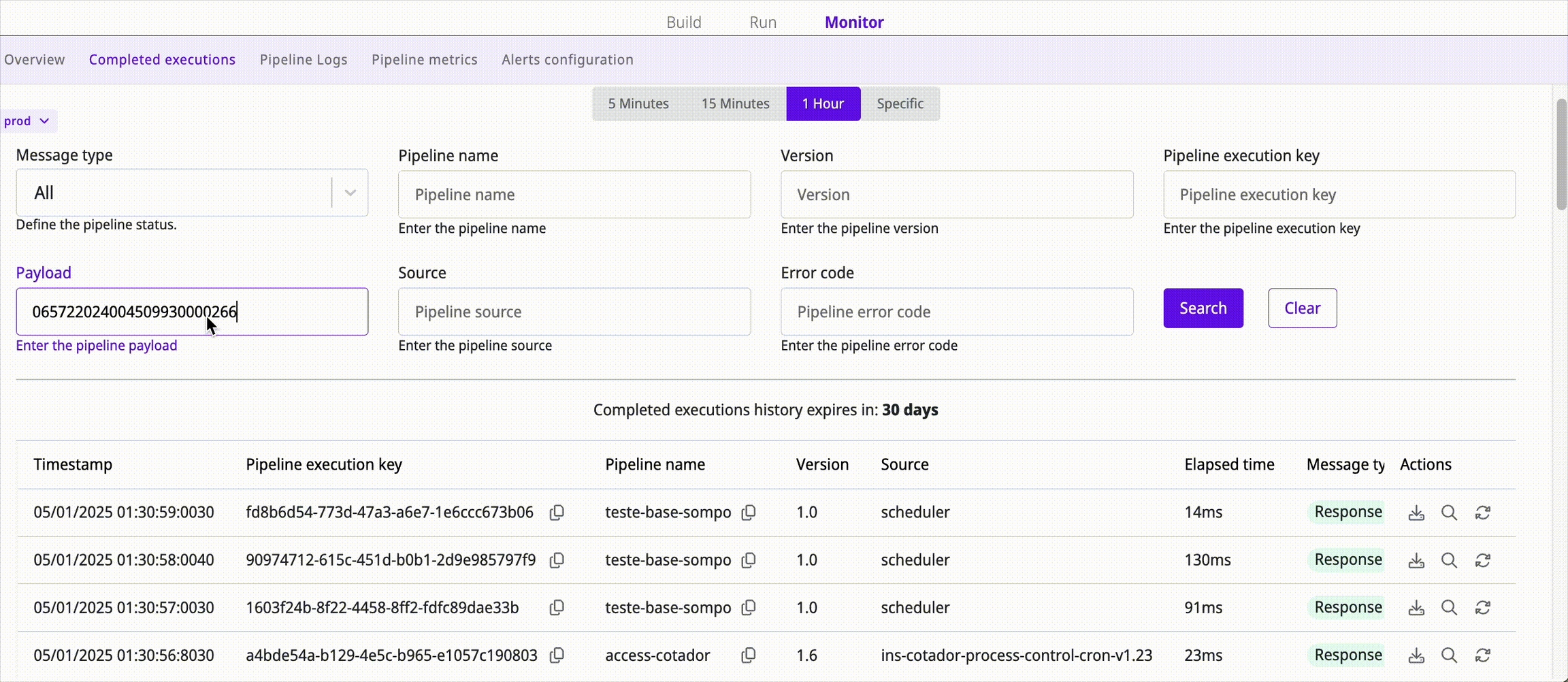
Manual reprocessing requires identifying the failed call and checking the previously used parameters. Depending on the configuration, you can keep the same parameters or change them. After reprocessing the call, perform a new search on the Pipeline logs page; it will be displayed with the value "manual" in the Source field.
Still having issues with your integration?
If so, open a ticket with our Support team. Here you can find out how to open a ticket and how long it is likely to take.
When you open the ticket, make sure you provide the relevant information:
Pipeline name or Execution ID
Previous analysis performed by the customer with proof of testing
Other pertinent information to help identify and analyze
Expected behavior versus observed behavior
Error message with date and time
Pipeline key (for errors or incidents)
Environment (Prod or Test)
Project name (if applicable)
Conclusion
By following the recommendations in this guide, you can troubleshoot pipelines on the Digibee Integration Platform more efficiently and independently. With an organized approach and the application of best practices — such as detailed log analysis, proper queue monitoring, and adjusting deployment settings — you can quickly identify and resolve common errors that affect integration execution.
The Digibee Integration Platform provides tools that, along with the troubleshooting procedures outlined, allow you to resolve many issues on your own. When necessary, use resources such as manual reprocessing and monitoring tools to validate corrections and ensure pipeline stability.
Last updated
Was this helpful?